How can specific production line processes like torque and run-down, press-fitting, or NHV testing be reimagined for Industry 4.0?
Much of the discussion around Industry 4.0 on the manufacturing line continues to focus on collecting data from and about the equipment that builds and assembles parts. This must broaden to include the data generated by the parts themselves during each production step.
A handful of automotive OEMs and suppliers get it and have done so for a long time. Others continue to struggle with the concept and focus too much on statistical process control data alone.
This is a digital transformation challenge that is not limited to smaller players. PricewaterhouseCoopers’ 2018 Global Digital Operations Study surveyed more than 1,100 executives at global manufacturing companies. Only 10% of these organizations fit PwC’s definition of ‘Digital Champion’. A full two-thirds have barely or not yet begun their digital journey.
It is a fallacy to think that if a large piece of equipment is operating within tolerances, all parts going through it will be built properly. Each part and each of its components is unique, with attributes that can stack up over the assembly process to affect the quality of the end product.
A key principle of any digital journey for a manufacturer, whether or not they are in the automotive supply chain, comes down to making effective use of production data. The more data you can collect and correlate in a manner that lends itself to easy analysis and visualization, the easier it is to see where process improvements can be made to boost quality and first-time yield. The exercise to trace root cause, to mitigate the impact of a recall or avoid a flood of warranty claims, becomes quicker and much easier.
Achieving this kind of insight doesn’t demand a reinvention of the wheel. It begins with what automotive OEMs and their suppliers are already doing – serialized production of parts, assemblies and finished vehicles.
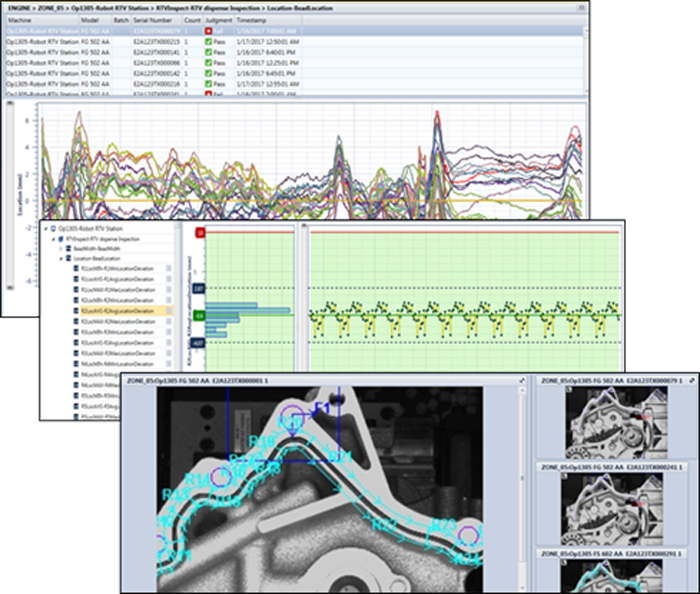
If a line is already producing output that is serialized, it’s only a small step to start collecting process and test data by serial number and organizing it into a birth history record. This data includes: binary pass/fail results (scalars); digital process signatures (waveforms such as sensor curves that capture and plot hundreds of thousands of data points per process or test cycle, just like an ECG); and machine vision images and data (in addition to the image itself, the scalars, arrays and strings that are associated with the image, which can be visualized as X/Y plots and integrated with the other process and test data).
The more data you can correlate and analyze, the easier it is for the quality team to catch any issue that could affect quality and yield. Instead of focusing on the data from and about the production equipment, the data from the parts being produced can raise a red flag about equipment issues before they lead to a pile of units that must be scrapped or reworked. Downstream quality issues can quickly be traced to their upstream cause. This enables preventative and predictive maintenance, to avoid the expense of unexpected downtime.
This kind of selective analysis doesn’t need a team of data scientists working days to find answers. Centralized data collection that breaks down the data silos on the plant floor, paired with modern off-the-shelf manufacturing analytics that feature user-friendly visualization tools, empower everyone from the front-line operator to the executive upstairs to become a data scientist. With the analytics capabilities available to manufacturers today, designed to scale for any size of production line, data-driven process improvement is far less complex than it once was.
The first step is a small one. Right-size what you need to achieve a desired outcome. It may be a persistent problem with sticky throttle assemblies, leaky transmissions or unbalanced electric motors. Pick one problem on the production line and consider what upstream processes could be contributing to it. From leak test, to press and rundown operations or sealant and adhesive dispensing, collect and analyze all the relevant data. This can provide immediate visibility into the impact of part and process variations, and the interaction between processes, that could be leading to that problem.
We have seen many examples where, by making a digital connection with each station and capturing the right kind and the right depth of data from every process, manufacturers have realized gains in throughput yield that saved them millions of dollars a year. The investment to achieve this cost saving was an order of magnitude less than the ROI.
For a plant that has yet to dip its toes into these data waters, baby steps are the best steps. Start with a specific problem on the line, see how modern data collection and analysis can help to find and address the root cause, and expand from there. The path to Industry 4.0 doesn’t have to be taken by leaps and bounds, nor should it be.